Francisco Requena
About
Categories
All
(10)
API
(1)
Genomics
(1)
R
(8)
animation
(4)
bayesian
(1)
bias
(1)
drug-discovery
(1)
genetics
(1)
human-genetics
(1)
machine-learning
(2)
networks
(1)
statistics
(2)
web-scrapping
(1)
The incredible robustness of the human genome
Genomics
In a recent interview, one of the most prolific Spanish researchers in the biomedical field, Carlos López Otín, stated the following:
Mar 20, 2024
Francisco Requena
Human genetics as a tool for drug discovery
drug-discovery
human-genetics
For children with a rare disease, an accurate diagnosis is crucial to provide advice, possible therapies and assess the potential risk for family members in future…
Jul 11, 2022
Francisco Requena
How many genes have been associated with cancer in PubMed?
API
R
bias
In the biomedical literature, it is common to find sentences like:
Mar 20, 2021
Francisco Requena
Extracting gene panels from the Genomics England Panelapp
web-scrapping
R
genetics
The Genomics England PanelApp provides panels of genes related to human disorders manually curated by healthcare experts. From a clinical and research perspective, this is a…
Mar 20, 2021
Francisco Requena
An introduction to ROC curves with animated examples
animation
R
machine-learning
Receiver operating characteristic (ROC) curves is one of the concepts I have struggled most. As a personal view, I do not find it intuitive or clear at first glance.…
Jun 12, 2020
Francisco Requena
An introduction to uncertainty with Bayesian models
animation
R
statistics
bayesian
In this post, we will get a first approximation to the “uncertainty” concept. First, we will train two models: logistic regression and its “Bayesian version” and compare…
May 29, 2020
Francisco Requena
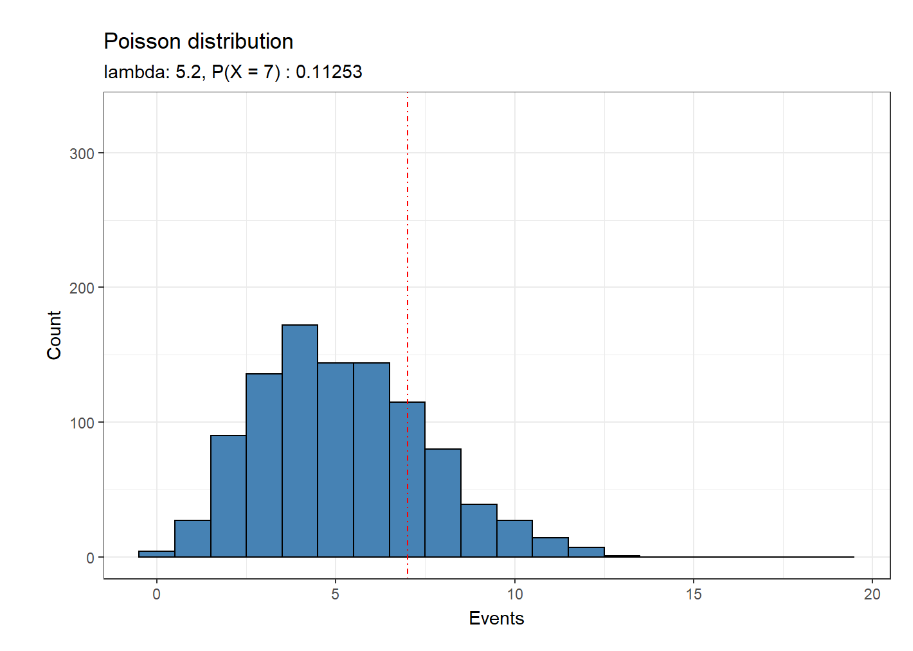
Poisson distribution in genomics
animation
R
statistics
In this post, I will discuss briefly what is the Poisson distribution and describe two examples extracted from research articles in the genomics field. One of them based on…
May 14, 2020
Francisco Requena
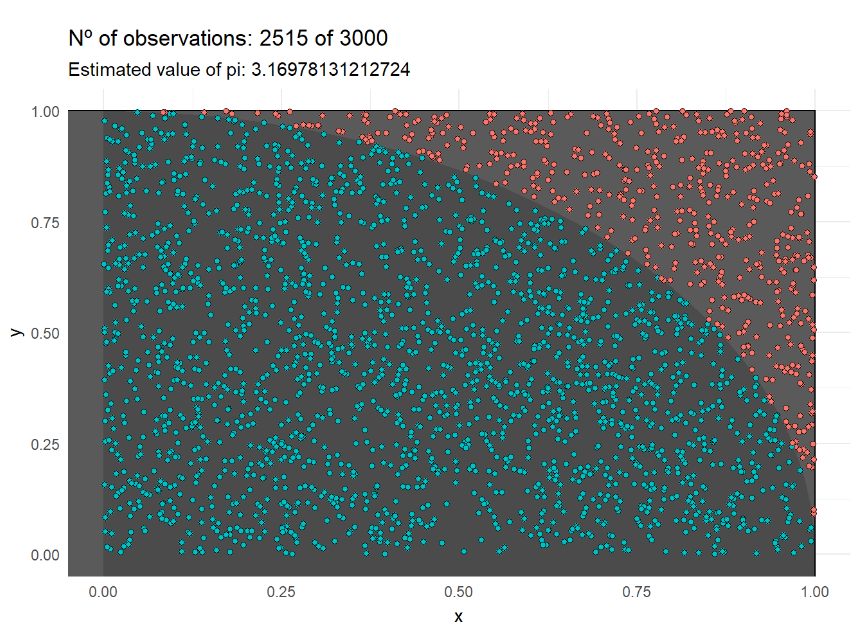
Estimating pi value with Monte Carlo simulation
animation
R
# Load of libraries
library
(tidyverse)
library
(sp)
library
(gganimate)
Mar 5, 2020
Francisco Requena
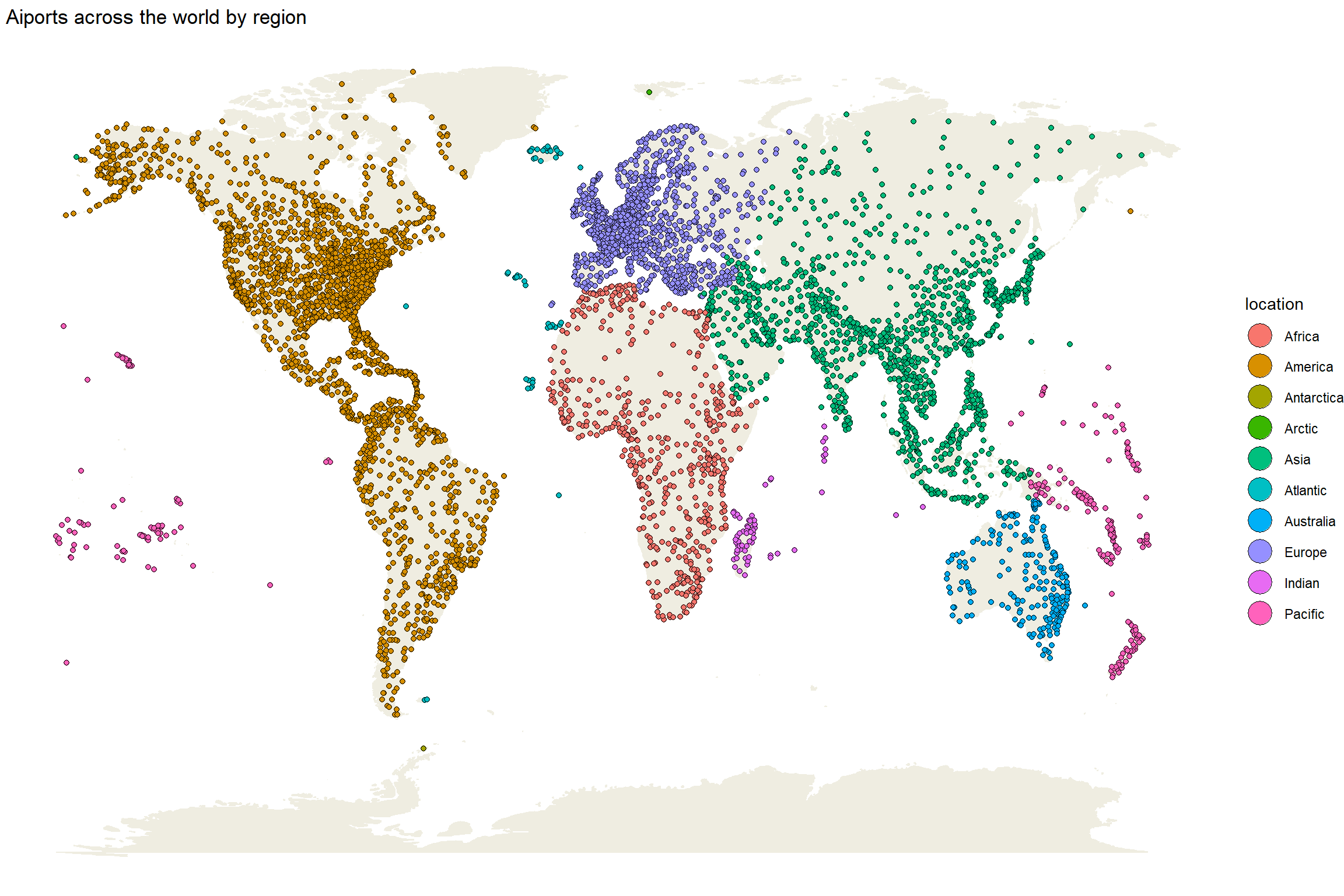
Exploring world flights with networks
networks
R
Recently, I started to read this free accessible book written by Albert-László Barabási. In the Chapter 4 of his book, it depicts the USA airport networks to
represent…
May 1, 2019
Francisco Requena
Prediction of dengue cases through climate variables
machine-learning
R
Recently, I discovered a new website about competitions that it is not called Kaggle! Its name is Drivendata.
Dec 9, 2017
Francisco Requena
No matching items